I recently presented a paper at the third LRL Workshop (a joint LTC-ELRA-FLaReNet-META_NET workshop on “Less Resourced Languages, new technologies, new challenges and opportunities”).
Motivation
The state of the art tools of the “web as corpus” framework rely heavily on URLs obtained from search engines. Recently, this querying process became very slow or impossible to perform on a low budget.
Moreover, there are diverse and partly unknown search biases related to search engine optimization tricks and undocumented PageRank adjustments, so that diverse sources of URL seeds could at least ensure that there is not a single bias, but several ones. Last, the evolving web document structure and a shift from “web AS corpus” to “web FOR corpus” (increasing number of web pages and the necessity to use sampling methods) complete what I call the post-BootCaT world in web corpus construction.
Study: What are viable alternative data sources for lesser-known languages?
Trying to find reliable data sources for Indonesian, a country with a population of 237,424,363 of which 25.90 % are internet users (2011, official Indonesian statistics institute), I performed a case study of different kinds of URL sources and crawling strategies.
First, I classified URLs extracted from the Open Directory Project (What are these URLs worth for language studies and web corpus construction?) and Wikipedia (Do the links from a particular edition point to relevant websites with respect to the language of the documents they contain?)
I did it for Indonesian, Malay, Danish and Swedish in order to enable comparisons, most notably with the Scandinavian language pair of medium-resourced languages. Then I performed web crawls focusing on Indonesian and using the mentioned sources as start URLs.
My scouting approach using open-source software leads to a URL database with metadata which can be used to replace or at least to complement the BootCaT approach.
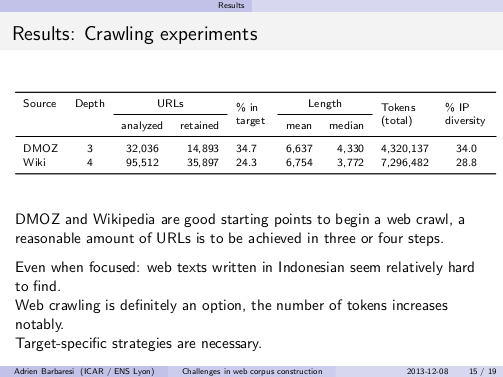 Slide from the talk: crawling experiments for Indonesian
Slide from the talk: crawling experiments for Indonesian
For more information
A. Barbaresi, “Challenges in web corpus construction for low-resource languages in a post-BootCaT world“, in Human Language Technologies as a Challenge for Computer Science and Linguistics, Proceedings of the 6th Language & Technology Conference, Less Resourced Languages special track, Zygmunt Vetulani and Hans Uszkoreit (eds.), pp. 69-73, Poznan, 2013.
The slides are also available from the HAL archive
The toolchain used in this article is available under an open-source license on GitHub: FLUX-Toolchain, Filtering and Language-identification for URL Crawling Seeds (FLUCS).
Selected references
- Barbaresi, A., 2013. “Crawling microblogging services to gather language-classified URLs. Workflow and case study”. In Proceedings of the Annual Meeting of the ACL, Student Research Workshop.
- Baroni, M. and Bernardini, S., 2004. “BootCaT: Bootstrapping corpora and terms from the web”. In Proceedings of LREC.
- Baroni, M., Bernardini, S., Ferraresi, A., Zanchetta, E., 2009. “The WaCky Wide Web: A collection of very large linguistically processed web-crawled corpora”. Language Resources and Evaluation, 43(3):209–226.
- Baykan, E., Henzinger, M., and Weber, I., 2008. “Web Page Language Identification Based on URLs”. Proceedings of the VLDB Endowment, 1(1):176–187.
- Borin, L., 2009. “Linguistic diversity in the information society”. In Proceedings of the SALTMIL 2009 Workshop on Information Retrieval and Information Extraction for Less Resourced Languages.
- Goldhahn, D., Eckart, T., Quasthoff, U., 2012. “Building Large Monolingual Dictionaries at the Leipzig Corpora Collection: From 100 to 200 Languages”. In Proceedings of LREC.
- Kilgarriff, A., Reddy, S., Pomikalek, J., and Avinesh, PVS, 2010. “A Corpus Factory for Many Languages”. In Proceedings of LREC.
- Lui, M., Baldwin, T., 2012. “Langid.py: An Off-the-shelf Language Identification Tool”. In Proceedings of the 50th Annual Meeting of the ACL.
- Scannell, K. P., 2007. “The Crubadan Project: Corpus building for under-resourced languages”. In Building and Exploring Web Corpora: Proceedings of the 3rd Web as Corpus Workshop, vol. 4.