Design decisions
Although text is ubiquitous on the Web, extracting information from web pages can prove to be difficult. They come in different shapes and sizes mostly because of the wide variety of platforms and content management systems, and not least because of varying reasons and diverging goals followed during web publication.
This wide variety of contexts and text genres leads to important design decisions during the collection of texts: should the tooling be adapted to particular news outlets or blogs that are targeted (which often amounts to the development of web scraping tools) or should the extraction be as generic as possible to provide opportunistic ways of gathering information? Due to a certain lack of time resources in academia and elsewhere, the second option is often best.
Consequently, an important problem remains as to the most efficient way to gather language data. Between CMS idiosyncrasies, bulky pages and malformed HTML, the chosen solution has to be precise, robust and fast at the same time. The purpose of this evaluation is to test currently available alternatives with respect to particular needs for coverage and speed.
The current benchmark focuses on Python, reportedly the most popular programming language in academia and one of the most popular overall. Some algorithms below are adapted from other languages such as Java and JavaScript, which gives a panorama of available solutions. Although a few corresponding Python packages are not actively maintained quite a few alternatives exist.
Alternatives
Trafilatura
Trafilatura is a library which downloads web pages, scrapes main text and comments while preserving some structure, and converts to TXT, CSV, XML & TEI-XML. It has been described in this previous blog post: Extracting the main text content from web pages using Python.
In the following, it is evaluated against other existing solutions on raw text extraction. The library can do more than that but not all contenders do, so the benchmark runs on a html2text setting. (Spoiler alert: it actually achieves the best results here and in independant benchmarks.)
Available alternatives
These packages keep the structure intact but do not focus on main text extraction:
- html2text converts HTML pages to Markup language
- inscriptis converts HTML to text with a particular emphasis on nested tables
The following packages focus on main text extraction:
- boilerpy3 is a Python version of the boilerpipe algorithm for boilerplate removal and fulltext extraction
- dragnet features combined indicators but requires more dependencies and fine-tuning
- goose3 can extract information for embedded content but doesn’t preserve markup
- jusText is designed to preserve mainly text containing full sentences along with some markup, it has been explicitly developed to create linguistic resources
- newspaper3k is mostly geared towards newspaper texts, provides additional functions but no structured text or comment extraction
- news-please is a news crawler that extracts structured information
- python-readability cleans the page and preserves some markup
Evaluation
The evaluation script is available on the project repository (see comparison.py). To reproduce the tests just clone the repository, install all necessary packages and run the evaluation script with the data provided in the tests directory.
Test set
The experiments below are run on a collection of documents which are either typical for Internet articles (news outlets, blogs) or non-standard and thus harder to process. Some contain mixed content (lists, tables) and/or non-standard not fully valid HTML code. They were selected from large collections of web pages in German, for the sake of completeness a few documents in English are added.
Evaluation
Decisive document segments are singled out which are not statistically representative but very significant in the perspective of working with the texts, most notably left/right columns, additional header, author or footer information such as imprints or addresses, as well as affiliated and social network links, in short boilerplate. Raw text segments are expected which is also a way to evaluate the quality of HTML extraction in itself.
Time
The execution time is not to be taken too seriously, the only conclusion at this stage is that goose3 and newspaper3k are slower than the rest while news-please performs a whole series of operations unrelated to text extraction.
Errors
The newspaper and boilerpipe modules do not work without errors on every HTML file in the test set, probably because of malformed HTML or parsing bugs.
Roadmap
Further evaluations coming up, including additional tools and languages. Comment extraction still has to be evaluated, although most libraries don’t offer this functionality.
Future evaluations will be described on the evaluation page.
Results
The following results are available both from the project repository and its documentation.
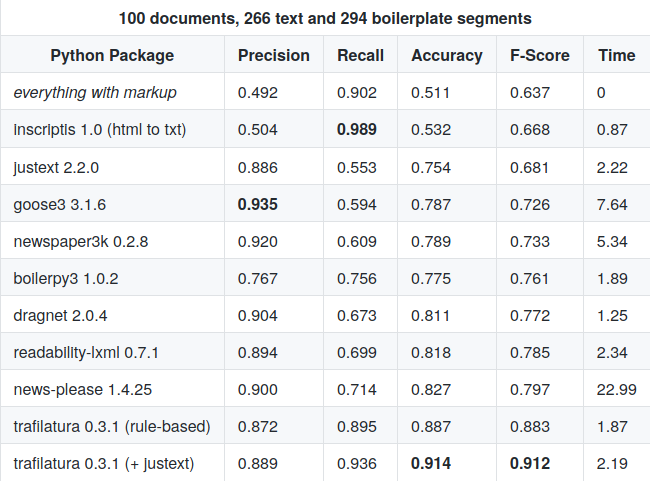
It turns out that rule-based approaches such as trafilatura‘s obtain balanced results overall, although they may lack precision on standard-compliant web documents. Both alone and combined with an algorithmic approach they perform significantly better on this dataset than the other tested solutions.
Update
Further comparisons have been made in the meantime. They are listed on the scraping evaluation page.
References
- Barbaresi, A. Trafilatura: A Web Scraping Library and Command-Line Tool for Text Discovery and Extraction, Proceedings of ACL/IJCNLP 2021: System Demonstrations, 2021, p. 122-131.
- Barbaresi, A. “Generic Web Content Extraction with Open-Source Software“, Proceedings of KONVENS 2019, Kaleidoscope Abstracts, 2019.
- Barbaresi, A. “Efficient construction of metadata-enhanced web corpora“, Proceedings of the 10th Web as Corpus Workshop (WAC-X), 2016.
- Barbaresi, A. Ad hoc and general-purpose corpus construction from web sources, PhD thesis, École Normale Supérieure de Lyon, 2015.