Introduction
Although text is ubiquitous on the Web, extracting information from web pages can prove to be difficult, and an important problem remains as to the most efficient way to gather language data. Metadata extraction is part of data mining and knowledge extraction techniques. Dates are critical components since they are relevant both from a philological standpoint and in the context of information technology.
In most cases, immediately accessible data on retrieved webpages do not carry substantial or accurate information: neither the URL nor the server response provide a reliable way to date a web document, i.e. to find when it was written or modified. In that case it is necessary to fully parse the document or apply robust scraping patterns on it.
State of the art
Diverse extraction and scraping techniques are routinely used on web document collections by companies and research institutions alike. Content extraction mostly draws on Document Object Model (DOM) examination, that is on considering a given HTML document as a tree structure whose nodes represent parts of the document to be operated on. Less thorough and not necessarily faster alternatives use superficial search patterns such as regular expressions in order to capture desirable excerpts.
Alternatives
The current benchmark focuses on Python, reportedly the most popular programming language in academia and one of the most popular overall. The purpose of this evaluation is to test currently available alternatives with respect to particular needs for coverage and speed: the chosen solution should ideally be precise, robust and fast.
The following open-source date extraction packages can be compared in a straightforward way:
- articleDateExtractor detects, extracts and normalizes the publication date of an online article or blog post,
- date_guesser extracts publication dates from a web pages along with an accuracy measure which is not tested here,
- goose3 can extract information for embedded content,
- htmldate is the software package I wrote to extract original and updated publication dates of web pages,
- newspaper is mostly geared towards newspaper texts,
- news-please is a news crawler that extracts structured information.
Two alternative packages are not tested here but could be used in addition:
- datefinder features pattern-based date extraction for texts written in English,
- if dates are nowhere to be found using CarbonDate can be an option, however this is computationally expensive.
Benchmark
Test set: The experiments below are run on a collection of documents which are either typical for Internet articles (news outlets, blogs, including smaller ones) or non-standard and thus harder to process. They were selected from large collections of web pages in German. For the sake of completeness a few documents in other languages were added (English, European languages, Chinese and Arabic).
Evaluation: The evaluation script is available on the project repository: tests/comparison.py. The tests can be reproduced by cloning the repository, installing all necessary packages and running the evaluation script with the data provided in the tests directory. Only documents with dates that are clearly to be determined are considered for this benchmark. A given day is taken as unit of reference, meaning that results are converted to %Y-%m-%d format if necessary in order to make them comparable.
Time: The execution time (best of 3 tests) cannot be easily compared in all cases as some solutions perform a whole series of operations which are irrelevant to this task.
Errors: goose3‘s output is not always meaningful and/or in a standardized format, these cases were discarded. news-please seems to have trouble with some encodings (e.g. in Chinese), in which case it leads to an exception.
Results
The following results are available on the project repository documentation.
They show that date extraction is not a completely solved task but one for which extractors have to resort to heuristics and guesses. The figures documenting recall and accuracy capture the real-world performance of the tools as the absence of a date output impacts the result.
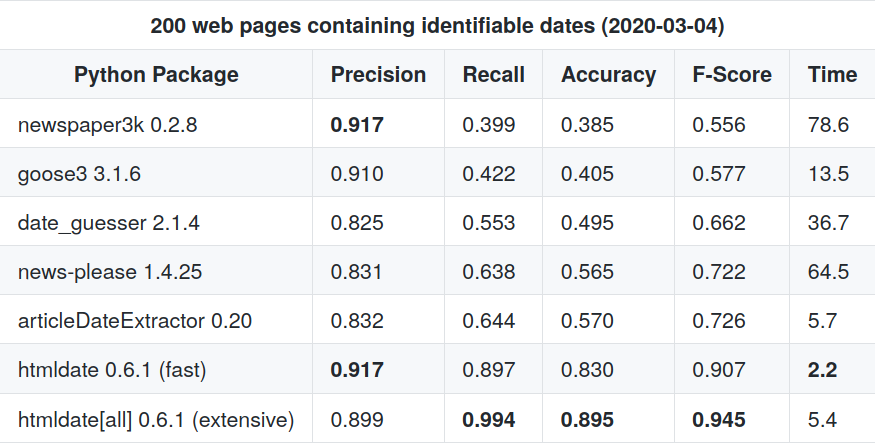
Precision describes if the dates given as output are correct: newspaper and goose3 fare well precision-wise but they fail to extract dates in a large majority of cases (poor recall). The difference in accuracy between date_guesser and newspaper is consistent with tests described on the website of the former.
It turns out that htmldate performs better than the other solutions overall. It is also noticeably faster than the strictly comparable packages (articleDateExtractor and date_guesser). Despite being measured on a sample, the higher accuracy and faster processing time are highly significant. Especially for smaller news outlets, websites and blogs, as well as pages written in languages other than English (in this case mostly but not exclusively German), htmldate greatly extends date extraction coverage without sacrificing precision.
Note on the different versions:
htmldate[all]means that additional components are added for performance and coverage. They can be installed withpip/pip3/pipenv htmldate[all]and result in differences with respect to accuracy (due to further linguistic analysis) and potentially speed (faster date parsing).- The
fastmode does not output as many dates (lower recall) but its guesses are more often correct (better precision).
Update
Further comparisons have been run in the meantime. They are listed on the date extraction evaluation page.
References
- Barbaresi, A. “htmldate: A Python package to extract publication dates from web pages“, Journal of Open Source Software, 5(51), 2439, 2020.
- Barbaresi, A. “Generic Web Content Extraction with Open-Source Software“, Proceedings of KONVENS 2019, Kaleidoscope Abstracts, 2019.
- Barbaresi, A. “Efficient construction of metadata-enhanced web corpora“, Proceedings of the 10th Web as Corpus Workshop (WAC-X), 2016.