I recently attended the Web as Corpus Workshop in Gothenburg, where I had a talk for a paper of mine, Finding viable seed URLs for web corpora: a scouting approach and comparative study of available sources, and another with Felix Bildhauer and Roland Schäfer, Focused Web Corpus Crawling.
Summary
The comparison I did started from web crawling experiments I performed at the FU Berlin. The fact is that the conventional tools of the “Web as Corpus” framework rely heavily on URLs obtained from search engines. URLs were easily gathered that way until search engine companies restricted this allowance, meaning that one now has to pay and/or to wait longer to send queries.
I tried to evaluate the leading approach and to find decent subtitutes using social networks as well as the Open Directory Project and Wikipedia. I take four different languages (Dutch, French, Indonesian and Swedish) as examples in order to compare several web spaces with different if not opposed characteristics.
My results distinguish no clear winner, complementary approaches are called for, and it seems possible to replace or at least to complement the existing BootCaT approach. I think that crawling problems such as link/host diversity have not been well-studied in a corpus linguistics context, and I wish to bring to linguists’ attention that the first step of web corpus construction in itself can change a lot of parameters.
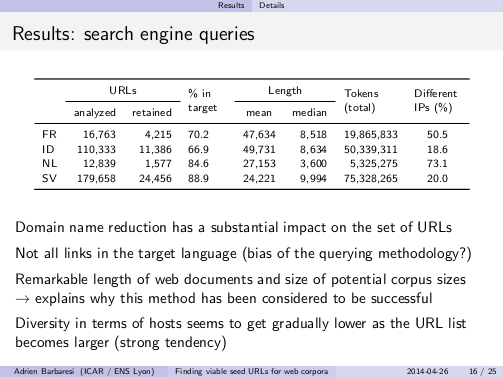
Slide on search engine URLs The slides of my talk can be downloaded here
Additionally, experiments run with Felix Bildhauer and Roland Schäfer at the FU Berlin showed that the crawling seeds I selected tend to perform better than the traditional approach.
References
For more information, the papers are available online:
-
A. Barbaresi, Finding Viable Seed URLs for Web Corpora: A Scouting Approach and Comparative Study of Available Sources, Proceedings of WaC-9, p. 1-8, 2014.
-
R. Schäfer, A. Barbaresi, F. Bildhauer, Focused Web Corpus Crawling, Proceedings of WaC-9, p. 9-15, 2014.
-
The toolchain used to perform these experiments is open-source and is available on GitHub: FLUX: Filtering and Language-identification for URL Crawling Seeds.