I already mentioned Amazon’s text stats in a post where I tried to explain why they were far from being useful in every situation: A note on Amazon’s text readability stats, published last December.
I found an example which shows particularly well why you cannot rely on these statistics when it comes to get a precise picture of a text’s readability. Here are the screenshots of text statistics describing two different books (click on them to display a larger view):
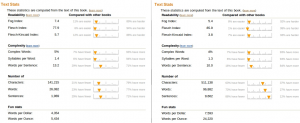
The two books look quite similar, except for the length of the second one, which seems to contain significantly more words and sentences.
The first book (on the left) is Pippi Longstocking, by Astrid Lindgren, whereas the second is The Sound and The Fury, by William Faulkner… The writing style could not be more different, however, the text statistics make them appear quite close to each other.
The criteria used by Amazon are too simplistic, even if they usually perform acceptably on all kind of texts. The readability formulas that output the first series of results only take the length of words and sentences into account and their scale is designed for the US school system. In fact, the “readability” and “complexity” factors are the same, so these sections are redundant. Nevertheless, it is an interesting approach to try to discriminate between them.
It is clear that the formulas lack depth and adaptability, we need to get a much more complete view of the processes that are concerned by readability issues (see for instance this post about Canadian research on readability in the ’90s).
Still, there may be other reasons that make the books comparable on this basic visualization. In the beginning of The Sound and The Fury, the characters are mostly speaking to a child. The ambiguity regarding the sentences and the narrative flow does not make its content that easy to understand, let alone the fact that the described reality is brutal. On the whole, Faulkner’s sentences are not particularly short, there are even a few luminous counterexamples, so there may be a failure in the text analysis, for instance in the tokenization process.
It is never easy to measure and to give precise data, as I discussed in
a . Once
again, one could ask for a more detailed account on readability, based
on two main questions : what kind of readability? and for whom?