This paper introduces a Twitter corpus focused geographically in order to (1) test selection and collection processes for a given region and (2) find a suitable database to query, filter, and visualize the tweets.
- Barbaresi, A. (2016). Collection and Indexing of Tweets with a Geographical Focus, in Proceedings of the 4th Workshop on Challenges in the Management of Large Corpora (LREC 2016), pp. 24-27.
Why Twitter?
“To do linguistics on texts is to do botanics on a herbarium, and zoology on remains of more or less well-preserved animals.”
“Faire de la linguistique sur des textes, c’est faire de la botanique sur un herbier, de la zoologie sur des dépouilles d’animaux plus ou moins conservées.”
Inaugural speech from Charles de Tourtoulon at the Académie des sciences, agriculture, arts et belles lettres, Aix-en-Provence, 1897. (For a detailed interpretation see the introduction of my PhD thesis)
Practical reasons
-
(Lui & Baldwin 2014)
- A frontier area due to their dissimilarity with existing corpora
-
(Krishnamurthy et al. 2008)
- Availability and ease of use
- Immediacy of the information presented
- Volume and variability of the data contained
- Presence of geolocated messages
My study of 2013 concerning other social networks (Crawling microblogging services to gather language-classified URLs) is not reproducible anymore due to API and terms of service changes.
Issues and design
Main issues related to the collection of Austrian tweets
- Mechanical constraints on the API (gardenhose streaming API: search terms or a geographic window, a fraction of corresponding data is returned)
- The population of the country is comparatively small
- Geolocated tweets are a small minority (2-3%)
- The success at being able to place users within a geographic region varies with the peculiarities of said region
Design
The corpus focuses on Austrian users, as data collection grounds on a two-tier detection process addressing corpus construction and user location issues. The emphasis lies on short messages whose sender mentions a place in Austria as his/her hometown or tweets from places located in Austria. The resulting user base is then queried and enlarged using focused crawling and random sampling, so that the corpus is refined and completed in the way of a monitor corpus.
Design decisions:
- A monitor corpus (possible to split the corpus in units of time): opportunistic collection + subcorpora
- Tweets sent from Austria vs tweets sent by Austrian users: subjective rather than “objective” component: user/location and user/description fields: places users feels related to
- Language cannot reliably be used as a proxy for location, so no language selection: difficulty to define a “national variety” for Standard Austrian German (Ebner 2008), few users found using “Austriacisms”
- No substitute for absent geolocation metadata
- Heavy tweeters and sampling processes: an open question, so far at random
 Schema of the implementation
Schema of the implementation
Results
The current volume (May 14th 2016) is 26,4 million tweets from 143,056 different users. This corpus is comparable to the German Snapshot (Scheffler 2014) in terms of volume with a number of users one order of magnitude smaller, which should then lead to a better yield overall.
The tweets are indexed using Elasticsearch and queried via the Kibana frontend, which allows for queries on metadata as well as for the visualization of geolocalized tweets (currently about 3.3% of the collection vs 1.1% for the German Snapshot)
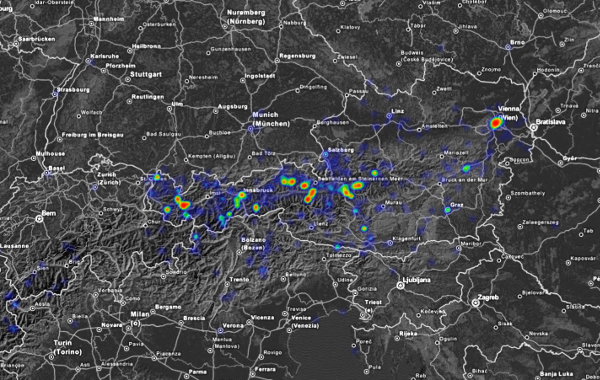 Results for geolocated tweets mentioning words beginning with ski
Results for geolocated tweets mentioning words beginning with ski
Conclusions
I presented a two-tier collection process addressing corpus construction and user location issues. The current volume is several millions of tweets per month.
Potentially interesting users are geographically and linguistically very mobile, and even among users who use geolocation services, the proportion of tweets with actual location data may vary greatly.
The E(L)K (Elasticsearch-Kibana) stack scales, so that further developments can be considered: a larger corpus (Germany + Switzerland), a state-of-the-art linguistic annotation, as well as the release of code and/or tweet IDs.
References
- Barbaresi A. (2013). Crawling microblogging services to gather language-classified URLs – Workflow and case study, in Procedings of the Annual Meeting of the Association for Computational Linguistics (Student Research Workshop), pp.9-15.
- Barbaresi, A. (2016). Collection and Indexation of Tweets with a Geographical Focus, in Proceedings of the 4th Workshop on Challenges in the Management of Large Corpora (LREC 2016), pp. 24-27.
- Ebner, J. (2008). Duden: Osterreichisches Deutsch. Dudenverlag.
- Krishnamurthy, B., Gill, P., and Arlitt, M. (2008). A Few Chirps about Twitter, in Proceedings of the First Workshop on Online Social Networks, pp. 19–24. ACM.
- Lui, M. and Baldwin, T. (2014). Accurate Language Iden- tification of Twitter Messages, in Proceedings of the 5th Workshop on Language Analysis for Social Media (LASM)@ EACL, pp. 17-25.
- Scheffler, T. (2014). A German Twitter Snapshot, in Proceedings of LREC, pp. 2284-2289.
- … for further references see article