Amazon’s readability statistics by example
I already mentioned Amazon’s text stats in a post where I tried to explain why they were far from being useful in every situation: A note on Amazon’s text readability stats, published last December.
I found an example which shows particularly well why you cannot rely on these statistics when it comes to get a precise picture of a text’s readability. Here are the screenshots of text statistics describing two different books (click on them to display a larger view):
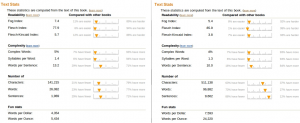
The two books look quite similar, except for the length of the second one, which seems to …
more ...